Pelle la tarte.
vcgencmd sur un Raspberry Pi avec une image Debian auto-fabriquée
J’ai acheté il y a quelque temps déjà un Rasperry Pi sur lequel j’ai mis une Debian Wheezy « standard » – comprenez « pas une Raspbian ». Pour cela j’ai suivi l’excellent tuto de Hödlmoser : http://blog.kmp.or.at/2012/05/build-your-own-raspberry-pi-image/
Mais ce n’est pas le sujet de ce post :)

Un outil permettant d’accéder à un bon nombre de paramètre du firmware du Raspberry existe : il s’agit de vcgencmd.
Dans mon cas, je voulais m’en servir pour récupérer la température interne du Raspberry, fournie par un capteur intégré au CPU.
Je suis tombé sur les problèmes suivant :
– vcgencmd n’était pas connu dans mon PATH. Bon ce n’est pas très grave, il suffit de l’appeler avec son chemin complet : /opt/vc/bin/vcgencmd, ou mieux, d’ajouter /opt/vc/bin au PATH. J’ai choisi de carrément ajouter /opt/vc/bin dans le PATH créé dans le fichier /etc/profile, qui sert de « PATH de base ».
– problème de librairie partagée non trouvée :
/opt/vc/bin/vcgencmd: error while loading shared libraries: libvcos.so: cannot open shared object file: No such file or directory
IL y a deux solutions à ce problème. Choisissez celle que vous préférez, inutile d’appliquer les deux.
La première solution (qui est plutôt une solution de contournement) que j’ai mise en oeuvre est de créer le script suivant dans /usr/local/bin (mais vous pouvez le placer dans n’importe quel dossier, pourvu qu’il soit dans votre PATH) :
LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/opt/vc/lib
export LD_LIBRARY_PATH
exec /opt/vc/bin/vcgencmd $@
Ce script positionne correctement la variable LD_LIBRARY_PATH pour lancer l’utilitaire vcgencmd. Le fait de placer ce script dans un dossier de votre PATH corrigera aussi le premier problème qui était que vcgencmd n’était pas connu dans le PATH.
La deuxième solution est d’ajouter la librairie manquante aux « PATH des librairies partagées système » de Linux.
Pour cela, créez un fichier dans /etc/ld.so.conf.d/. Le nom du fichier doit finir par .conf (vcgen.conf par exemple).
Dans ce fichier, il n’y a qu’une ligne à mettre :
Passez la commande ldconfig pour appliquer les changements.
Le dossier /opt/vc/lib/ est maintenant utilisé pour la recherche des librairies partagées et la librairie manquante, libvcos.so, sera trouvée.
Il faut tout de même ajouter /opt/vc/bin/ à votre PATH ou bien créer un script (ou un lien) dans un dossier de votre PATH pour lancer la commander vcgencmd sans avoir à écrire tout le chemin.
L’avantage de la 1ère solution est que le dossier /opt/vc/lib ne sera scruté que lorsque vous lancerez la commande vcgencmd (via le script). L’inconvénient c’est que c’est un peu brouillon, et que vous risquez de retomber sur le même problème pour un autre programme qui aurait besoin de cette librairie partagée, ou bien d’une autre librairie partagée contenue dans /opt/vc/lib.
Pour la 2ème solution c’est l’inverse : elle est plus universelle car toutes les librairies partagées de /opt/vc/lib seront scrutées pour tous les programmes. L’inconvénient est que du coup, il y a une petite perte de performances. C’est négligeable lorsque l’on ajoute seulement un dossier qui contient quelques librairies partagées comme ici, mais ajouter de nombreux dossiers, contenant chacun de nombreuses librairies, peut affecter les performances du système puisque ce dernier va scruter toutes les librairies partagées indiquées (jusqu’à trouver la bonne) quand il devra chercher une librairie partagée.
Au final, j’ai choisi :
– d’ajouter /opt/vc/bin/ au « PATH de base » créé dans /etc/profile
– la 2ème solution pour le problème de la librairie partagée manquante
PS : quand même, un petit exemple d’utilisation de vcgencmd pour récupérer la température interne du Raspberry :
temp=56.8'C
Liens utiles :
– A propos de LD_LIBRARY_PATH : http://www.cc.dtu.dk/?page_id=304
– Ajouter des librairies partagées à Linux : http://blog.andrewbeacock.com/2007/10/how-to-add-shared-libraries-to-linuxs.html
– A propos de vcgencmd : http://elinux.org/RPI_vcgencmd_usage
– Pour créer sa propre image Debian pour son Raspberry : http://blog.kmp.or.at/2012/05/build-your-own-raspberry-pi-image/
Munin : configurer le temps de rafraîchissement
Par défaut, le temps de rafraîchissement des données dans Munin est de 5 min. Dans certains cas, ce temps n’est pas adapté aux mesures que l’on veut effectuer.
A partir de la version 2.0 de Munin, il est possible de configurer ce temps, moyennant tout de même quelques manipulations.
Dans cet article, je vais vous montrer comment configurer Munin pour avoir un rafraîchissement toutes les minutes, mais vous pouvez configurer une autre période.
Il n’est pas possible facilement de descendre en dessous de la minute. Si vous voulez descendre sous la minute, il faudra bidouiller cron comme ici par exemple.
Attention : tous les plugins doivent partager la même périodicité, donc ils doivent tous êtres compatibles avec la périodicité que vous choisissez.
Etape 1
Arrêter munin. Si un noeud est présent sur le serveur Munin, arrêter aussi munin-node.
Si possible, arrêter les cron de munin et munin-node. Mettez en commentaire les lignes concernées dans /etc/cron.d/munin et /etc/cron.d/munin-node.
Si pour une raison ou une autre il ne vous est pas possible de faire cette dernière manipulation, ce n’est pas très grave (vous aurez juste des erreurs qui vont sortir dans les logs).
Etape 2
Dans /etc/munin/munin.conf, ajouter :
# permet de configurer le nombre de données gardées dans les
# fichiers rrd (donc la taille des fichiers, et la granularité des données)
graph_data_size custom 1d, 5m for 1w, 15m for 1y, 1h for 5y
# Voir aussi :
# http://munin-monitoring.org/wiki/format-graph_data_size
# http://oss.oetiker.ch/rrdtool/doc/rrdtool.en.html
Etape 3
Adapter le cron de munin : dans /etc/cron.d/munin modifier la ligne :
par la ligne :
Etape 4
Dans /var/lib/munin : supprimer tous les fichiers (laisser les dossiers)
Supprimer les fichiers (.rrd) dans les dossiers correspondant aux noms des domaines
Etape 5
Supprimer les logs (c’est plus simple pour retrouver les nouvelles erreurs) dans /var/log/munin
Attention : laisser les fichiers munin-cgi-graph.log et munin-cgi-html.log (ou bien les recréer vides avec les droits -rwxr-x— 1 www-data www-data)
Etape 6
Redémarrer munin et munin-node :
Décommentez les lignes dans les fichiers /etc/cron.d/munin et /etc/cron.d/munin-node le cas échéant.
Voilà, normalement c’est tout bon!
Quelques remarques importantes
Tous vos graphes seront réinitialisés, vous perdrez toutes les données mesurées jusqu’à maintenant.
La taille des fichiers RRD peut augmenter considérablement en fonction des paramètres que vous choisissez à l’étape 2. Je vous conseille de lire http://munin-monitoring.org/wiki/format-graph_data_size.
Mettre un temps de rafraîchissement très court sur une grosse installation peut affecter considérablement les performances de votre serveur.
Installation de MyTinyTodo sur Debian avec Apache/MySQL
J’ai vu un article sur le blog de Nicolargo à propos d’un outil en ligne, libre et qu’il est possible d’auto-héberger qui permet la gestion de ses « todo-lists » personnelles : mytinytodo. Je ne reviendrai pas sur cet article très bien fait, voici simplement la méthode d’installation de mytinytodo sur le couple Apache/MySQL (l’article de Nicolargo traite de l’installation sur NGinx/SQLite).
Toutes les commandes de cet article sont passées en tant que root.
Prérequis
Avoir un apache qui fonctionne, avec les sites dans /var/www/
Si ça n’est pas déjà fait, installer le paquet php5-mysql :
Avoir un MySQL fonctionnel.
Installation
Configuration MySQL
Se connecter à MySQL :
Dans MySQL, passer les commandes suivantes :
GRANT ALL privileges ON mytinytodo.* TO 'mytinytodo'@'localhost';
SET password FOR 'mytinytodo'@'localhost' = password('mytinytodopwd');
quit
Vous pouvez bien sur changer le nom de la base de données, de l’utilisateur et du mot de passe, mais pensez à bien reporter ces changements à l’étape de configuration de mytinytodo.
Installation de mytinytodo
Passer les commandes suivantes :
wget http://mytinytodo.googlecode.com/files/mytinytodo-v1.4.2.zip
unzip mytinytodo-v1.4.2.zip
rm mytinytodo-v1.4.2.zip
cd /var/www/mytinytodo/lang/
wget http://www.mytinytodo.net/lang/zip/fr.zip
unzip fr.zip
rm fr.zip
sudo chown -R www-data:www-data /var/www/mytinytodo
Configuration de mytinytodo
Allez à l’adresse : http://votre_adresse/mytinytodo/setup.php
Choisissez MySQL et les options suivantes :

Le Password est « mytinytodopwd » que vous avez configuré dans MySQL.
Finalisation
Supprimer /var/www/mytinytodo/setup.php :
Utilisation
Là, je vous recommande la lecture de l’article de Nicolargo, je ne ferai pas mieux =)
Vous pouvez bien sur aussi aller vous balader sur le site de mytinytodo et notamment sur la page de démo.
Références
Blog de Nicolargo : http://blog.nicolargo.com/
Site de mytinytodo : http://www.mytinytodo.net
Installation de GateOne : nouveau client SSH en HTML5
J’ai déjà parlé dans un précédent article d’ajaxterm, un client SSH web, et de la manière de l’intégrer à Apache.
Un nouveau client SSH web vient de sortir : GateOne. Grosse différence : il est en HTML5 ! Enfin, il y a toujours du python derrière, mais le client, dans un navigateur, utilise bien l’HTML5. Par contre, il est encore en beta, et j’ai des soucis avec le clavier français par exemple (ce qui n’est pas très pratique, notamment pour les mots de passe…). Bon, c’est très prometteur, et ces bugs de jeunesse devraient être corrigés assez rapidement.
Procédure d’installation (sur Debian, mais ça devrait être à peu près pareil sur d’autres distributions, au gestionnaire de paquets près) :
1) Mise à jour de la distribution :
apt-get upgrade
2) Installation des prérequis :
pip install tornado pyopenssl
3) Téléchargement des sources :
4) Installation :
python setup.py install
5) Lancement de GateOne :
./gateone.py
Si, comme moi, vous avez déjà quelque chose qui tourne sur le port 443 (apache, à priori…) vous aurez l’erreur suivante :
File "./gateone.py", line 1212, in
main()
File "./gateone.py", line 1203, in main
http_server.listen(options.port, options.address)
File "/usr/local/lib/python2.6/dist-packages/tornado/netutil.py", line 100, in listen
sockets = bind_sockets(port, address=address)
File "/usr/local/lib/python2.6/dist-packages/tornado/netutil.py", line 265, in bind_sockets
sock.bind(sockaddr)
File "", line 1, in bind
socket.error: [Errno 98] Address already in use
En effet, GateOne écoute sur le port 443 par défaut. Le fichier de configuration est généré à la première utilisation, mais on peut maintenant l’éditer :
Remplacer le port spécifié par un port libre. Vous pouvez maintenant relancer GateOne, et y accéder à l’adresse : https://ip.de.votre.serveur:port
Une dernière astuce : je conseille de lancer GateOne avec la commande nohup, histoire qu’il continue de fonctionner après que vous ayez quitté le terminal dans lequel vous l’avez lancé :
Pour l’arrêter, il faudra par contre killer le process du coup.
Voilà, on attend maintenant la correction des quelques bugs qui restent!
Sources :
http://korben.info/client-ssh-html5.html
http://tiennot.fr/romain/index.php?post/2011/10/15/Installer-Gate-One-Client-SSH-en-HTML5
https://github.com/liftoff/GateOne
http://liftoff.github.com/GateOne/About/index.html
Gimp warp tool: c’est la mi-parcours !
Et voilà, on est déjà à la mi-parcours pour le Google Summer of Code, et je n’ai pas posté de mise à jour comme je le voulais. Il faut croire que réflechir et coder reste plus amusant pour moi qu’écrire. Néamoins, corrigeons ça.
Le moins que l’on puisse dire, c’est que l’outil warp (il va falloir que je trouve une traduction française) est en bien meilleure forme que l’outil cage à la même époque l’an dernier. La raison est simple, j’ai appris énormement l’an passé, et il faut bien avouer que l’outil warp fait appel à des compétences similaires, voir reprend quelques portions de code.
Ceci étant dit, voilà le bilan:
- Toute l’infrastructure de l’outil est en place et fonctionnelle.
- On peut appliquer des déformations directement sur le canvas.
- 7 comportements sont supportés actuellement:
- déplacement de pixels
- grossissement d’une zone
- rétrécissement d’une zone
- spirale dans le sens horaire
- spirale dans le sens anti-horaire
- effacement local d’une transformation
- lissage local d’une transformation
- Les actions sur le canvas se font grâce à un pinceau rond, avec une courbe d’influence gaussiene.
- Les réglages du pinceau sont la force, la taille et la dureté de la courbe d’influence (plus ou moins raide).
Une petite vidéo pour la forme:
Les différentes opérations effectuées sur le canvas sont implémentées comme des opérations Gegl qui produisent un buffer de coordonées relatives, que l’on insère dans le graph de rendu. L’image finale est calculée grace à une opération de rendu map-relative.

Et voilà ce qu’il reste à corriger:
- Les performances restent à améliorer. Actuellement, à chaque action sur l’image, chaque opérations déjà effectuées est recalculées (le cache ne fonctionne pas correctement), et ce pour toute la surface de l’image (un problème dans le code historique qui n’a pas été conçu pour ça). D’autres pistes d’amélioration existent, comme l’implémentation du Copy On Write (COW) pour les GeglBuffer. Le but final est d’effectuer les actions de manière interactive.
- Un bon réglage est nécessaire, les différents comportements ne sont pas cohérents actuellement.
- Implémenter l’interface selon les spécifications de Peter Sikking et de son équipe.
- Implémenter l’annulation des opérations.
Comme j’ai plus de facilités cette année, j’en profite pour aller un peu plus en profondeur et de travailler sur des choses annexes, en particulier dans Gegl. Une chose intéressante est de constater que l’outil warp est structurellement assez proche d’un moteur de dessin (dans le sens pinceau), et fait donc un pas de plus vers un moteur de dessin basé sur Gegl dans Gimp.
NAS Synology: Debian en chroot, apache et mysql
Le système d’exploitation embarqué dans les NAS Synology, le DSM, est un système plutôt sympathique à utiliser, et qui permet de s’éviter des heures de configuration. Activer un serveur ftp en 2 clics est assez appréciable.
Quand on veut aller plus loin, avoir une configuration apache particulière, utiliser screen + irssi, et toutes ces choses qui ne sont pas prévus par le fabriquant, cela devient plus compliqué. Même si obtenir un accès SSH root est très facile, on tombe sur des consoles qui ne sont pas en UTF-8, avec un busybox énervant, un système de paquet obsolète avec un choix limité. Et surtout, on risque de casser le système en bidouillant la configuration, qui est assez tentaculaire, et régénérée en partie à chaque changement dans l’interface.
Il y a une solution que je trouve assez élégante à ce problème, c’est d’installer une Debian en parallèle du système de base, grâce à debootstrap et un chroot. Dit comme ça, ça a l’air bien compliqué, mais en réalité, c’est plus simple et moins risqué que de triturer le DSM, avec en bonus, toute la puissance de Debian. Le principe est que nous allons ’embarquer’ une Debian sur le NAS, qui va tourner dans un compartiment restreint, le chroot. Nous aurons donc les deux systèmes qui tournent en parallèle, les deux faisant des appels au même noyaux, celui du DSM.
 Mise en place de Debian
Mise en place de Debian
{kind=link}
Il va nous falloir une Debian qui tourne quelque part pour générer un système de base. Si vous n’en avez pas, vous pouvez l’installer dans une machine virtuelle le temps de faire la manip (Debian net-install et Virtualbox font très bien l’affaire). Un fois ceci fait, on va utiliser debootstrap de nous générer une archive minimale pour notre architecture cible, l’ARM :
mkdir sdebian
sudo debootstrap --foreign --arch armel squeeze sdebian
sudo tar -cvzfp sdebian.tar.gz sdebian
Transférez l’archive obtenue sur votre NAS, placez la dans /volume1/, connectez vous au NAS grâce à telnet et désarchivez la :
Mise en place du chroot
Debian aura besoin de faire des appels au noyau linux du DSM. Nous allons donc rendre accessible dans le chroot les répertoires spéciaux comme /proc, /dev …
On va utiliser un petit script shell qui va nous permettre de faire les quelques opérations nécessaires et d’entrer dans le chroot. Éditez un fichier chroot.sh, et copiez y les commandes suivantes:
mount -o bind /dev $CHROOT/dev
mount -o bind /proc $CHROOT/proc
mount -o bind /dev/pts $CHROOT/dev/pts
mount -o bind /sys $CHROOT/sys
cp /etc/resolv.conf $CHROOT/etc/resolv.conf
# Si installation d'un apache sur le port 80 dans Debian,
# voir la suite de l'article
# /usr/syno/etc.defaults/rc.d/S97apache-user.sh stop
chroot $CHROOT /bin/bash
Executez le en root, et vous serez dans le chroot. Il reste maintenant à finaliser l’installation de Debian :
Générez un fichier sources.list correct grâce à http://debgen.simplylinux.ch, et placez le dans /etc/apt/sources.list.
Une petite mise à jour de Debian:
apt-get upgrade
Ajout d’un compte utilisateur:
J’ai du corriger quelques droits d’accès qui se sont perdus dans la bataille. Il y en a probablement d’autres, à vous de corriger si nécessaire.
chmod +t /tmp
Installation du minimum vital:
Pour que la Debian soit fonctionnelle, il faut maintenant faire tourner un certain nombre de services. Sur une Debian normale, ces services sont lancés par init, mais ce n’est pas notre cas. Il faudra donc les lancer manuellement. Éditez un fichier services.sh que vous placerez dans votre $HOME, et placez y le contenu suivant :
/etc/init.d/mtab.sh start
/etc/init.d/cron start
/etc/init.d/ssh start
/etc/init.d/uptimed start
# Si installation d'apache et de mysql, voir la suite de l'article
# /etc/init.d/apache2 start
# /etc/init.d/mysqld start
Et voilà, votre Debian est fonctionnelle ! Vous avez virtuellement deux systèmes qui tournent en parallèle. Si votre NAS s’éteint, vous devrez lancer le script chroot.sh, qui vous emmène dans la Debian, puis le script services.sh. Si vous vous connectez en telnet, vous tomberez sur le DSM, et en ssh, sur Debian.
Installation d’apache et de mysql
Le DSM fait déjà tourner deux apache, un pour l’interface web, l’autre pour les web station et photo station. L’un des deux écoute sur le port 80, et redirige vers l’interface web (port 5000/5001) si nécessaire. Si vous voulez faire tourner un apache sur le port par défaut, il va falloir faire deux choses:
- Allez dans l’interface d’administration et activez la web station
- Arrêtez le deuxième apache par telnet:
Après installation d’apache et de mysql, pensez à dé-commenter les lignes correspondantes dans les deux scripts. On a perdu au passage les web et photo stations, mais si vous voulez un apache personnalisé, c’est probablement que vous n’en avez pas besoin. Si vous changez d’avis, vous pouvez toujours réactiver le service apache du DSM, la configuration est restée intacte.
Conclusion
A l’usage, c’est une solution très efficace. Les services avancés du NAS d’un coté, la simplicité et la puissance de Debian de l’autre. La différence se situe au niveau de l’occupation en RAM, même si cela reste bien raisonnable. Après 20 jours d’uptime, l’occupation mémoire est de 170Mo sur 512Mo, sachant que Linux à tendance à ne pas trop nettoyer la mémoire s’il n’en a pas besoin.
Source:
Edit: meLIanTQ a proposé une solution pour un lancement automatique du chroot au démarrage du NAS: Le commentaire
On da road again !

Et voilà. Cette année encore, je vais participer au programme Google Summer of Code !
Ma participation à l’édition de l’an dernier aura été pour moi un énorme défi, un moyen d’apprendre énormément de chose, de rencontrer et côtoyer des gens très intéressants, et une grande source de fierté (même pour ma famille, c’est dire si le nom de Google veut dire quelque chose pour la société d’aujourd’hui).
Cette année, je vais pouvoir mettre à profit toutes ces connaissances engrangés l’an dernier pour réécrire l’ancien plugin iWarp comme un véritable outil interne à Gimp (dont le petit nom sera le Gimp Warp tool). C’est un outil qui a longtemps été demandé par les utilisateurs de Gimp. Là encore, cet outil s’intégrera dans la « grande vision » du futur de Gimp (Gegl, prévisualisation directement sur l’image, ..).
D’un point de vue plus personnel, il est clair que ma tâche de cette année présente moins de défi que l’an dernier (un autre outil de déformation, structure relativement proche ..), et c’est presque dommage. Néanmoins, c’est toujours sympathique de travailler sur un projet comme Gimp, et les utilisateurs le rendent bien la plupart du temps. Et puis, il faut bien faire travailler son cerveau pendant l’été =)
Cette fois, je devrais être capable de faire cet outil de la bonne façon, dès la première fois (et donc éviter les 3 ou 4 réécritures partielles qui ont suivit la période officielle de développement du programme Summer of Code). Avec un peu de chance, cet outil pourrait être intégré à Gimp 2.8. Le début de la période de code est finalement pas si loin !
A bientôt !
Installer ajaxterm sur un NAS Synology et y accéder en https
Ajaxterm est un terminal dans une page web, accessible donc simplement par un navigateur web. Les avantages? Il est accessible de partout, quelque soit le proxy, pare-feu, antivirus, ou n’importe quelle protection mise en place, du moment que le http/https passe. Les inconvénients : c’est un peu lent, et pas sécurisé si vous ne passez pas par de l’https.
J’ai un peu galéré, mais j’ai fini par réussir à installer ajaxterm sur mon NAS Synology et à configurer son accès en https. Comme ça peut servir à d’autres (private : je vise personne :D ), voilà ma méthode.
1) Installation de python 2.5
Ajaxterm nécessite python pour fonctionner, donc il faut l’installer :
2) Installation d’ajaxterm
Téléchargez ajaxterm :
Extraire les fichiers :
Éditez le fichier ajaxterm.py et modifiez la ligne suivante en remplaçant localhost par l’IP de votre NAS :
Je ne sais pas pourquoi, je n’ai pas réussi sans cette manip. 127.0.0.1 ou localhost ne fonctionnent pas, il faut vraiment mettre l’IP de votre NAS sur votre LAN (192.168.0.X en général).
Copiez le dossier Ajaxterm-0.10 où bon vous semble, ajaxterm ne « s’installe » pas plus que ça. Tout ce qui est nécessaire est dans ce dossier, que vous pouvez mettre n’importe où.
Pour lancer ajaxterm, c’est tout simplement, dans le dossier Ajaxterm-0.10 :
A ce stade, vous pouvez normalement accéder à ajaxterm à l’adresse : http://ip.de.votre.nas:8022/
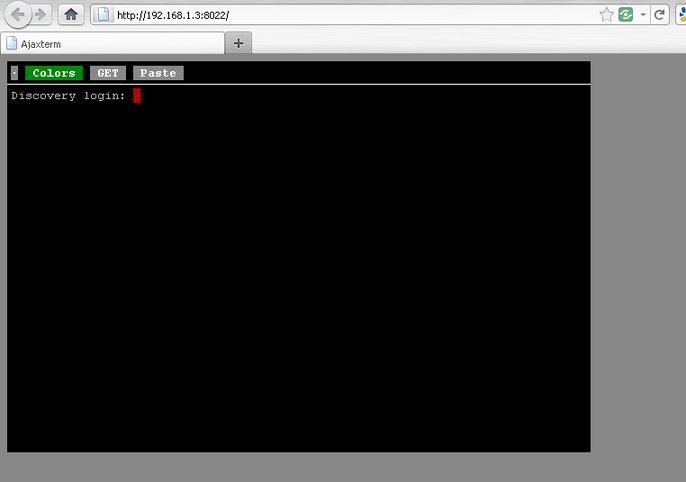
Mise en place de l’accès https par apache
Etant donné qu’il y a déjà un apache d’installé sur les NAS Synology, configuré de manière (très) particulière, et qu’il sert à accéder à l’interface d’administration du NAS, on va éviter de le casser :)
J’ai opté pour l’installation d’un second apache, avec ipkg :
Ce nouvel apache ne sera pas accessible sur le port 80 puisque celui-ci est déjà utilisé par l’apache d’origine. Par contre, il est à l’écoute sur le port 8000, et vous devriez avoir accès à la célèbre page « It works! » à l’adresse http://ip.de.votre.nas:8000
Pour info, l’arrêt/relance de ce nouvel apache se fait avec les commandes suivantes :
Editez la configuration https d’apache : /opt/etc/apache2/extra/httpd-ssl.conf
Il faut apporter les modifications suivantes :
--------------------------------------------------------------------Listen 443Listen 4430 (vous pouvez mettre un autre port) --------------------------------------------------------------------<VirtualHost _default_:4430>NameVirtualHost *:4430 <VirtualHost *:4430> --------------------------------------------------------------------DocumentRoot "/opt/share/www"ServerName www.example.com:443ServerAdmin you@example.comErrorLog "/opt/var/apache2/log/error_log"TransferLog "/opt/var/apache2/log/access_log"ServerName localhost --------------------------------------------------------------------
Et ajouter les lignes suivantes juste avant la balise :
--------------------------------------------------------------------
ProxyRequests Off
Order deny,allow
Allow from all
ProxyPass /ajaxterm/ http://ip.de.votre.nas:8022/
ProxyPassReverse /ajaxterm/ http://ip.de.votre.nas:8022/
--------------------------------------------------------------------
Une dernière chose : il est plus propre d’utiliser le certificat déjà présent sur le nas. C’est tout simple :
rm /opt/etc/apache2/server.key
ln -s /usr/syno/etc/ssl/ssl.crt/server.crt /opt/etc/apache2/server.crt
ln -s /usr/syno/etc/ssl/ssl.crt/server.key /opt/etc/apache2/server.key
Relancez apache, et normalement c’est tout bon! Vous avez accès en https à votre ajaxterm à l’adresse suivante : https://ip.de.votre.nas:4430/ajaxterm/
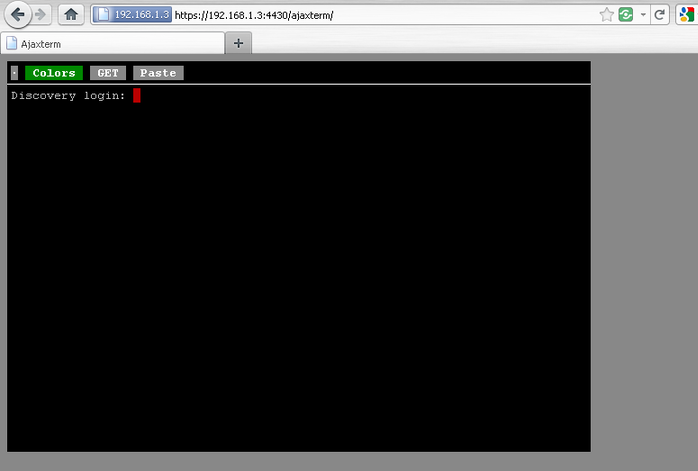
Remarques
– Ajaxterm semble ne pas fonctionner sous Firefox 3.6 sous Linux. Je n’ai pas encore trouvé pourquoi. Ca fonctionne par contre correctement sous Chrome et Firefox 4.0 sous Linux, et sous toutes les versions de Firefox sous Windows (en fait ça fonctionne sans doute dans toutes les autres configurations…)
– Je ne suis pas sur de la fiabilité de la configuration apache donnée ici. Elle fonctionne mais je ne vous garantie pas qu’elle est sure à 100% vu que je n’ai pas encore vraiment compris l’organisation particulière de la configuration d’apache installée avec ipkg.
Quelques new de l’outil cage

Cela fait maintenant quelques temps que je n’ai pas posté de news a propos de de l’outil cage. Il est même resté quelques mois sans changements, quand je me suis mis en tête de coder un ERP adapté au Junior-Entreprise. J’y ai passé quelques heures aujourd’hui, et je me suis dit qu’il serait temps de faire un petit bilan des changements depuis ce temps:
- comme annoncé précédemment, une réécriture de la gestion de l’interface sous forme d’une machine à état, avec pas mal de nettoyage (et quelques régression également, il faut avouer)
- utilisation d’une structure de donnée spécifique, ce qui permet ..
- la sélection multiple des poignées, avec une sélection par ruban, pour pouvoir éditer une cage plus rapidement, ou simplement la bouger en entier d’un coup
- la possibilité de revenir dans dans le mode d’édition de la cage, et ajuster la cage de départ
- quelques optimisations dans l’opérateur Gegl qui effectue la transformation
Il reste des bugs à attraper, le plus évident étant que l’image se décale après un retour en mode d’édition. Mais promis, ça sera près pour la sortie de Gimp 2.8 ! D’ailleurs, les dernières corrections se feront a partir de maintenant dans la branche master de Gimp, donc ce n’est plus la peine de récupérer la branche de l’outil.
Pour fêter tout ça, j’ai fait un rapide screencast avec un lézard comme victime.
Incruster des sous-titres dans un film avec mencoder
Un mini-post ultra rapide sur une technique pour incruster des sous-titres dans un film au format avi avec mencoder :
On retrouve cette commande dans la doc Ubuntu.